.svg)

.svg)
%202.svg)
'가끔 팔리는 제품'은 왜 예측이 힘들까? 간헐적 수요예측이 어려운 이유

많은 기업이 수요 예측을 통해 재고를 관리하고 공급망을 운영합니다. 그러나 모든 제품이 꾸준히 팔리는 것은 아닙니다. 실제 산업에서는 오랫동안 판매가 없다가 특정 시점에 갑자기 주문이 발생하는 간헐적 수요 또는 불규칙 수요가 매우 흔합니다.
이러한 수요는 예측하기 더 어렵습니다. 단순히 변동성이 큰 것이 아니라, 수요가 발생하는 구조 자체가 다르기 때문입니다.
시장에는 ‘가끔 팔리는 제품’이 많습니다
온라인 쇼핑몰이나 제조업을 보면, 제품이 수천 개에서 수만 개까지 존재하는 경우가 흔합니다.
그중 일부 제품은 매일 또는 매주 꾸준히 팔립니다. 이런 제품은 판매 패턴이 비교적 안정적이기 때문에, 과거 판매 데이터를 기반으로 미래 판매량을 예측하기가 상대적으로 쉽습니다.
반면, 많은 제품들은 그렇지 않습니다. 어떤 제품은 몇 달 동안 전혀 판매되지 않다가 갑자기 특정 시점에 주문이 들어오는 경우가 있습니다. 이런 제품은 판매가 연속적으로 이어지는 것이 아니라 가끔 발생합니다.

이런 판매 구조는 흔히 파레토 법칙이나 롱테일(long-tail) 구조로 설명되곤 합니다. 매출 대부분은 소수 제품이 차지하지만, 제품 수 기준으로 보면 대부분은 판매 빈도가 낮은 품목들입니다.
문제는 바로 이 제품들입니다. 기업이 관리해야 할 SKU의 상당수가 이런 간헐적 수요를 가지고 있습니다.
그래서 재고 의사결정은 더 어려워집니다. 수요 발생 시점을 알기 어렵기 때문에 재고를 적게 두면 품절 위험이 커지고, 많이 두면 재고 비용이 증가합니다. 결국 간헐적 수요 예측은 단순한 통계 문제가 아니라, 재고 관리와 공급망 운영 시 중요한 문제가 됩니다.
간헐적 수요는 무엇이 다를까요?
간헐적 수요는 단순히 판매량이 적은 수요가 아닙니다. 핵심은 판매가 이어지지 않는다는 점입니다.
예를 들어 이런 경우를 생각해볼 수 있습니다. 어떤 제품이 10주 동안 한 번도 팔리지 않다가 11주 차에 주문이 들어오는 것입니다. 그리고 다시 몇 주간 판매가 발생하지 않습니다. 또한 수요가 발생했을 때의 규모 역시 일정하지 않습니다. 어떤 날은 1개가 팔리지만, 어떤 날은 50개가 팔립니다.
이 예시는 간헐적 수요의 핵심 특징 두 가지를 보여줍니다.
- 얼마나 자주 발생하는가
- 발생했을 때 얼마나 크게 움직이는가
이런 수요를 체계적으로 분석하기 위해 연구자들은 간헐적 수요를 정량적으로 구분하는 기준을 발전시켜 왔습니다. 수요 발생 간격(ADI)과 변동성(CV²) 같은 지표를 사용합니다.
ADI (Average Demand Interval)는 수요가 발생하는 평균 간격을 뜻합니다. 쉽게 말해 ‘평균적으로 얼마의 기간마다 한 번씩 수요가 발생하는가”’를 나타냅니다. CV²(Squared Coefficient of Variation)는 수요가 발생했을 때 크기의 상대적 변동성을 나타냅니다. 값이 클수록 수요 크기의 불확실성이 크다고 이해할 수 있습니다.
이 두 지표를 사용하면 수요는 네 가지 유형으로 나뉩니다.
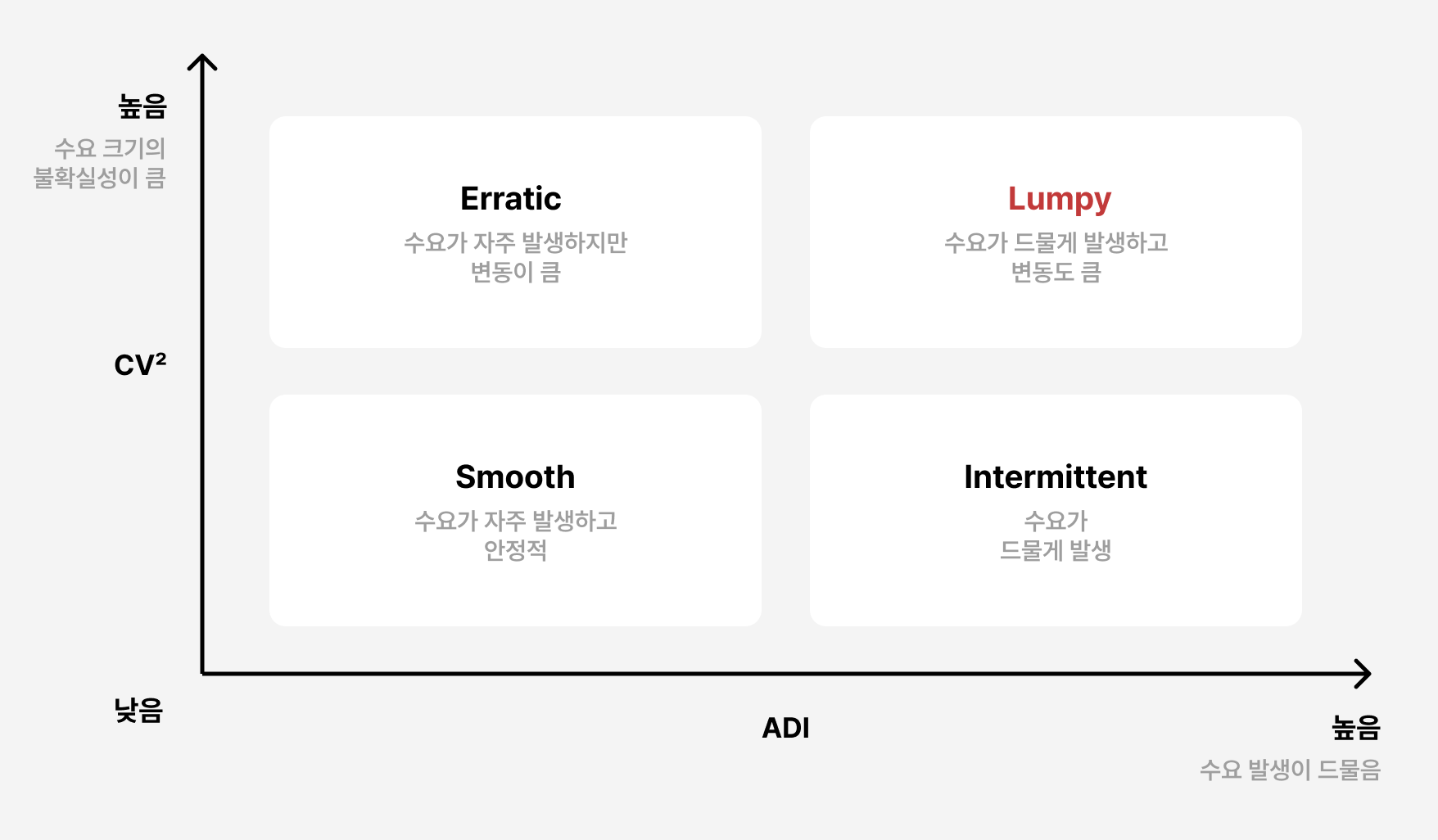
그중 Lumpy 수요는 발생 간격도 길고 규모 변동도 커서 가장 예측이 어렵지만, 실제 산업 환경에서는 많은 제품이 Intermittent 또는 Lumpy 영역에 속합니다.
왜 기존 예측 방법이 잘 맞지 않는 이유
이런 간헐적 수요에서는 기존 예측 방식이 잘 맞기 어렵습니다. 지수평활이나 ARIMA 같은 전통적인 시계열 모델은 물론이고, 머신러닝이나 딥러닝 모델 역시 마찬가지입니다.
기존 예측 방법들은 기본적으로 ‘과거에 반복된 패턴’을 학습합니다. 이때 매주 꾸준히 수요가 발생한다면, 평균 수준이나 변동 폭을 계산하기도 쉽고, 계절성이나 추세 같은 구조도 비교적 안정적으로 파악할 수 있습니다. 하지만 간헐적 수요에서는 대부분의 기간에 수요가 발생하지 않으며, 실제로 수요가 발생한 데이터가 너무 적습니다.
예를 들어 어떤 제품이 1년 동안 단 3번만 팔렸다면, 이 제품의 평균 판매량을 계산하는 것을 신뢰할 수 있을까요? 이 경우 수요가 발생한 관측 자체가 매우 적기 때문에 통계적 구조를 추정하는 것이 어렵습니다.
또한 시계열 모델에서 중요한 개념인 자기상관 구조(과거 값이 미래 값에 영향을 주는 패턴)도 충분한 관측이 없으면 제대로 추정하기 어렵습니다.
간헐적 수요예측 방법의 발전
간헐적 수요를 따로 다루려는 시도는 오래전부터 있었습니다. 가장 먼저 등장한 방법은 수요를 발생 간격(Inter-arrival interval)과 ‘발생했을 때의 크기(Demand size)로 나누어 계산하는 방식이었습니다. (Croston, 1972)
이 접근은 간헐적 수요를 구조적으로 바라봤다는 점에서 의미가 있었지만, 일부 상황에서는 평균 수요를 실제보다 조금 크게 예측하는 경향이 있었습니다. 이후 이를 보완해 예측값을 보다 현실에 가깝게 조정한 방식이 등장했습니다. (Syntetos & Boylan, 2005)
그 다음에는 수요가 발생하는 가격을 직접 보는 대신, ‘지금 이 시점에 수요가 발생할 가능성은 얼마나 되는가’를 직접 추정하는 방식도 제안되었습니다. (Teunter, Syntetos & Babai, 2011)
최근에는 아예 수요를 확률 과정으로 보고, 0이 자주 발생하는 구조 자체를 모델 안에서 설명하려는 방법까지 발전하고 있습니다.
그런데 왜 여전히 어려울까요?
지금까지의 방법들은 중요한 발전이었지만, 공통적으로 ‘관측된 수요 데이터를 어떻게 추정할 것인가’에 초점을 두고 있습니다.
하지만 간헐적 수요는 본질적으로 두 단계 구조를 가집니다.
- 수요가 발생하는가?
- 발생했다면 얼마나 발생하는가?
즉 간헐적 수요는 발생 여부와 발생 규모 두 가지 확률로 구성된 것입니다. 하지만 기존의 접근 방식들은 이를 하나의 값으로 처리합니다. 그래서 수요가 왜 이런 형태로 나타나는지를 충분히 설명하지 못하는 것입니다.
간헐적 수요를 ‘사건’으로 이해하면 더 쉽습니다
간헐적 수요를 연속적인 흐름이 아니라 어떤 사건이 드물게 발생하는 과정으로 이해하면 더 쉽습니다. 예를 들어, 장비 고장이 발생했을 때 혹은 교체 시점이 도래했을 때 부품 수요가 발생하는 것입니다.
이 관점에서는 데이터가 적은 이유와 예측이 어려운 이유를 함께 설명할 수 있습니다.
간헐적 수요예측의 핵심은 ‘구조’
간헐적 및 불규칙적 수요는 많은 산업에서 매우 자연스럽게 나타나는 현상입니다. 이러한 수요는 기존 시계열 예측 방식이 전제로 하는 반복되는 패턴이 부족하기 때문에 구조적으로 예측이 어렵습니다.
간헐적 수요 문제는 단순히 예측 알고리즘을 더 복잡하게 만든다고 해결되지 않을 수 있습니다. 데이터가 부족한 상황에서는 관측값 자체보다 관측값이 생성되는 구조를 이해하는 것이 더 중요할 수 있기 때문입니다.
따라서 간헐적 수요를 제대로 이해하고 예측하기 위해서는 수요를 앞서 설명한 사건 기반 확률적 생성 과정으로 해석하는 관점이 필요합니다.
간헐적 수요를 실제로 어떻게 모델링할 수 있을까요?
지금까지 살펴본 것처럼, 간헐적 수요는 단순한 시계열 문제가 아니라 ‘발생 여부’와 ‘발생 시 규모’가 결합된 확률적 생성 구조를 가집니다.
문제는 이 구조를 실제 현업 데이터에 적용 가능한 형태로 구현하는 일입니다. 이론적으로는 발생 확률과 조건부 수요 규모를 분리해 설명할 수 있지만, 실제 데이터에서는 관측이 희소하고 노이즈가 많으며, 수요 특성이 시간에 따라 변하기도 합니다.
기존의 많은 방법들은 평균 수요율을 추정하거나 발생 확률을 계산하는 데 초점을 두어 왔습니다. 그러나 현장에서는 품목별 데이터가 충분하지 않기 때문에, 개별 시계열만으로는 안정적인 추정이 어렵습니다.
따라서 간헐적 수요 예측에서는 다음과 같은 접근이 필요합니다.
- 수요를 하나의 흐름이 아니라 생성 구조로 해석하고
- 발생 여부와 발생 규모를 분리하여 모델링하며
- 희소 데이터 환경에서도 안정적으로 학습할 수 있어야 합니다.
임팩티브AI는 이러한 관점에서 간헐적 수요를 단순한 연속 시계열로 보지 않습니다. 수요 발생 구조 자체를 학습하는 방식으로 접근하여, 발생 여부와 발생 규모를 분리해 모델링합니다.
특히 관측이 제한적인 상황에서도, 품목 간 정보를 활용해 수요 패턴을 안정적으로 추정하도록 설계하고 있습니다.
간헐적 수요 예측의 핵심이 ‘구조 이해’라면, 그 다음 단계는 그 구조를 실제 데이터에 맞게 구현하는 일입니다. 이 지점에서 예측 모델의 설계 방법이 중요한 차이를 만듭니다.
간헐적 수요예측 어려움으로 고민하고 계신다면, 임팩티브AI와 함께 새로운 접근을 경험해보세요.
참고 문헌
- Croston, J. D. (1972). Forecasting and stock control for intermittent demands. Operational Research Quarterly.
- Syntetos, A. A., & Boylan, J. E. (2005). The accuracy of intermittent demand estimates. Journal of the Operational Research Society.
- Teunter, R., Syntetos, A., & Babai, M. (2011). Intermittent demand: Linking forecasting to inventory obsolescence. International Journal of Forecasting.
- Lambert, D. (1992). Zero-inflated Poisson regression, with an application to defects in manufacturing. Technometrics.
- Box, G. E. P., Jenkins, G. M., Reinsel, G. C., & Ljung, G. M. (2015). Time Series Analysis: Forecasting and Control (5th ed.). Wiley.
- Hyndman, R. J., Koehler, A. B., Ord, J. K., & Snyder, R. D. (2008). Forecasting with Exponential Smoothing. Springer.
.svg)


.svg)






