.svg)

.svg)
%202.svg)
Can AI Predict Sales for New Products Too?

How Company W Achieved Up to 94% Accuracy Without Historical Sales Data
Initial purchase orders for new products are always decided before launch. The challenge is that, at that stage, there is not yet enough sales data available.
This was especially true for the product lines operated by global lifestyle content company W. Unlike typical products with steady, repeat sales over long periods, W’s products followed a launch-driven sales structure in which demand was heavily concentrated within a short time after release. Product configurations and sales periods also varied significantly, making it difficult to compare past products using a single standard.
In this type of product environment, the first purchase order directly determines both inventory risk and missed sales opportunity risk. If the order quantity is too conservative, initial demand may be lost. If it is too aggressive, excess inventory can remain after the short selling period ends.
The key question W wanted to answer together with Impactive AI was clear:
"Can we predict demand for new products with no historical sales data for the exact same item — using only limited early demand signals — at a level reliable enough for first-order decision-making?"
Impactive AI conducted a blind test on W’s major new-product SKUs and achieved 75–94% accuracy in high-sales-volume segments. In particular, products with large sales volumes recorded 87–94% accuracy, demonstrating a level of prediction reliability practical enough for first-order planning decisions.
Why Forecasting W’s New Products Was Difficult
The reason new-product demand forecasting is difficult is simple: there is no historical sales data for the exact product being forecasted. However, for W, the challenges went even further.
1. New Products Had No Historical Reference Data
Demand forecasting is typically based on historical sales records and statistical data. Since new products have no sales history, conventional forecasting methods cannot be directly applied.
In practice, planners may rely on experience and intuition, thinking: “This product seems similar to Product A from the past.” “This configuration may follow a demand pattern similar to Product B.”
While this approach benefits from practical experience, it also heavily depends on individual memory and judgment. Forecasting consistency can vary when personnel change or when no obvious comparable product comes to mind.
2. Sales Periods and Product Configurations Varied by Product
W’s new products were not sold under consistent conditions.
Some products were available only for short periods, while others remained on sale longer. Product compositions, options, and packaging also changed each time.
As a result, it was difficult to compare all new products using a single standardized time-series framework.
3. Demand Was Concentrated in the Early Launch Phase
W’s major product categories showed a common pattern: sales surged immediately after launch and then declined rapidly afterward.
For products with such strong early-demand concentration, misreading initial demand can lead to significant errors in first-order quantities.
Ultimately, W’s challenge was not merely about improving forecast accuracy. The real challenge was:
How can we build a reliable forecasting structure and comparison framework for first-order decision-making even when historical data is limited?
Impactive AI’s Approach to New Product Forecasting: Three Key Questions
Impactive AI did not attempt to solve W’s forecasting challenge with a single model alone.
Instead, the problem was divided into three practical business questions aligned with actual decision-making processes:
- Which historical products are most similar to this new product?
- During which periods is demand concentrated?
- Which AI-generated forecast values require additional business validation?
W’s forecasting framework was designed around these three questions.
1. Finding Similar Historical Products Through Data
New products do not have their own historical sales records. However, even products that appear completely new may still share characteristics with previously sold items.
Traditionally, planners selected comparable products manually based on experience: “This item resembles Product A.” “This configuration may show demand patterns similar to Product B.”
Although practical experience is valuable, such judgments are inherently subjective.
Impactive AI transformed this process into a data-driven approach. Using both numerical and categorical product attributes, the system quantitatively calculated similarity between new and historical products.
In cases where sufficiently similar products did not exist within the same category, the search scope was expanded to adjacent categories. This ensured that every new product could have at least a minimum comparison benchmark.
The core value of this approach was not simply identifying similar products. It was about turning experience-based judgment into a reproducible, data-consistent decision framework.
2. Standardizing Different Sales Durations Into Three Sales Phases
Finding similar products alone did not fully solve the problem.
W’s products had different sales durations:
- Some products sold for only a short period
- Others remained available longer
If all products were modeled using one unified time-series structure, meaningful comparisons became difficult.
Impactive AI therefore viewed sales curves not as one continuous timeline, but as three standardized phases:
- Launch: Initial sales period immediately after release
- Mid: Middle sales period
- Deadline: Final sales period before sales end
By dividing the sales lifecycle into phases, products with different sales durations could still be compared using a common framework.
Even short-selling and long-selling products could be transformed into the same structural pattern of Launch, Mid, and Deadline phases.
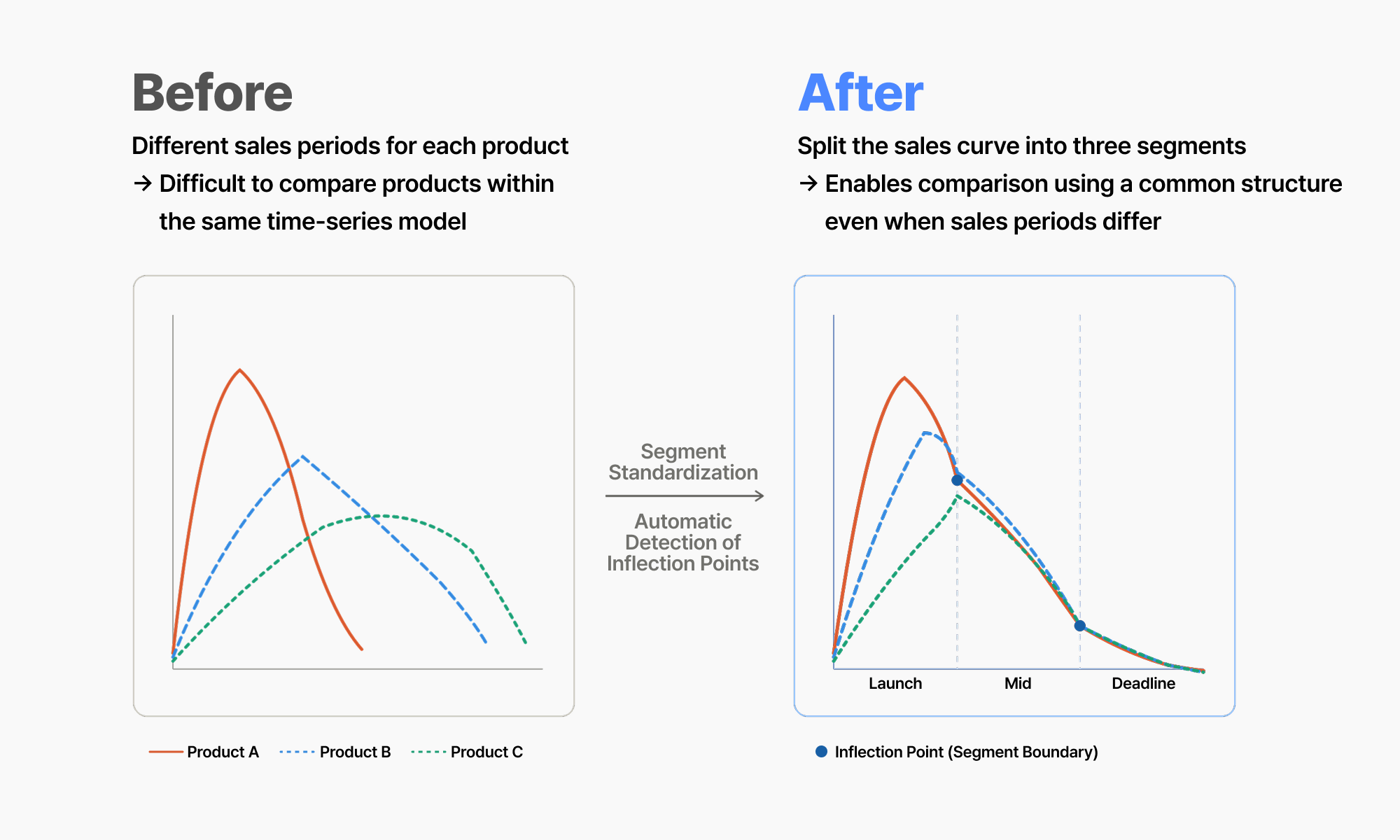
In addition, Impactive AI applied automated change-point detection methods to identify turning points in sales curves. Multiple detection logics — including statistical change detection, distribution-based outlier analysis, and distance-based heterogeneity detection — were combined to determine where sales patterns shifted.
As a result, W’s products could be forecasted within a unified structure despite differences in sales duration.
3. Applying Business Validation Beyond Raw AI Predictions
In demand forecasting, building a model is only part of the challenge. It is equally important to verify whether the model outputs are practically reasonable for business operations.
Especially for new products, similarity matching may not always be perfect, and prediction variance may occur across different phases.
Therefore, instead of directly using raw AI outputs, Impactive AI implemented a multi-stage post-processing correction framework.
For the W project, forecast results were validated in two directions:
- Excessively high predictions were adjusted downward
- Excessively low predictions were adjusted upward
At each correction stage, the following factors were reviewed together:
- Comparisons between new and historical products
- Internal consistency within the new product itself
- Alignment between predicted values and actual trend patterns
The framework was also designed to prevent duplicate corrections on the same product across multiple stages.
This was not a process of blindly trusting AI outputs. Rather, it was a safeguard to ensure AI-generated forecasts could be reliably used in real operational decision-making.
Forecast Results: 75–94% Accuracy in Major Sales Segments
Impactive AI conducted blind tests on W’s major launch-driven new-product SKUs.
The results showed:
- 75–94% accuracy for products with sales volumes above 1,000 units
- 87–94% accuracy for high-volume products exceeding 10,000 units
The importance of these results goes beyond high prediction accuracy alone.
W previously lacked historical sales records for identical products when determining initial purchase quantities. Through this project, however, the company was able to establish practical forecasting benchmarks for major product groups using only limited early-stage data signals.
The validation process was also conducted conservatively:
- Expanding Window Validation was applied by progressively extending the training period
- Target new products were excluded from both training and reference datasets in blind-test evaluations
- WMAPE was used as the evaluation metric to reflect differences in sales volume scale
The Key to New Product Forecasting Is Not Data Volume — It’s the Approach
New products inherently have no historical data. This condition is unlikely to change in any industry.
That is why the core challenge of new-product forecasting is not simply collecting more data. The real issue is how to design a forecasting structure that remains effective even with limited historical information.
Through the W project, Impactive AI identified three essential principles:
- Historical comparison products must be identified using data-driven criteria
- Different sales patterns must be standardized into a comparable structure
- AI-generated forecasts must be validated once more using business logic
Together with Impactive AI Deepflow, W successfully addressed these three questions.
Companies managing launch-driven products with short sales cycles and highly concentrated demand likely face similar challenges. Even when historical sales data is limited, changing the forecasting approach can significantly expand what is predictable.
See Whether New Product Forecasting Is Possible for Your Business
If your company operates launch-driven products with short sales cycles and concentrated demand — or if limited historical sales data makes first-order planning difficult — Impactive AI's Deepflow Forecast can help diagnose what is possible for your business.
👉 Contact Us Now
.svg)

.svg)









