.svg)

.svg)
Download Brouchure
%202.svg)
Oops! Something went wrong while submitting the form.

More companies than ever are adopting AI-powered demand forecasting solutions, yet the line between success and failure remains razor-sharp. It all comes down to two factors: data readiness and modeling strategy. According to a 2026 CEO survey, 46% of executives identified data quality and volume as the single most important factor in AI investment.
No matter how sophisticated an AI algorithm may be, it cannot produce accurate predictions from poor-quality data. Conversely, even the richest, most refined datasets will fall short if paired with a model that doesn't match their characteristics. Research into failed AI demand forecasting projects reveals that over 70% of failures stem from inadequate data preparation and misguided model selection.
The evolution of demand forecasting in 2026 is heading toward self-correcting models, where AI detects prediction errors in real time and determines whether they originate from data quality issues or structural market shifts, then autonomously recalibrates itself. The backbone of this evolution is a robust data foundation paired with the right model architecture.
Once you've decided to adopt a demand forecasting solution, the very first step is to accurately gauge your organization's current data readiness level. Many companies assume that having large volumes of data is enough, but in practice, the structure and quality of that data matter far more than sheer quantity.
Data typically resides across multiple systems—ERP for sales, WMS for inventory, CRM for customer interactions—and different departments often interpret the same data differently. To address this, 2026 best-practice guidelines recommend organizing metadata on an "intent-ready" basis, enabling AI agents to autonomously understand and navigate data assets. For example, whether "sales volume" refers to shipment volume or order volume must be clearly documented so that AI can independently locate and use the right information.
From a data quality engineering perspective, variables with missing values exceeding 20% should generally be excluded from the model. High missing-value ratios increase model variance and create excessive dependence on interpolated data, ultimately distorting predictions. When interpolation is necessary, it's recommended to use statistical methods that account for seasonality rather than relying on simple averages.
Outlier treatment deserves special attention, particularly where business context must take priority. For instance, data from promotional periods like Black Friday may appear as statistical outliers, but they actually represent critical demand patterns that the model needs to learn. In addition, organizations should aim to build intelligent detection systems by 2026 that validate POS data in real time and block contaminated data from entering the pipeline, thereby ensuring data reliability at the source.

The transformer-based architectures that dominate 2026 demand significantly more GPU memory and computational resources than legacy LSTM models. Hardware capability assessments should therefore come first. To mitigate network bottlenecks, an "edge-cloud hybrid" strategy—where data undergoes initial processing at the point of origin before being sent to the cloud—is gaining strong traction.
By structuring causal relationships between products, suppliers, weather conditions, and promotions through knowledge graphs, AI can move beyond simple correlations and learn to interpret market dynamics in a multidimensional way. Walmart, for example, has built digital twins for over 1,700 stores, running pre-validation scenarios in virtual environments to maximize forecasting precision.
Data poisoning attacks targeting AI models have become a tangible threat in 2026. Research shows that as few as 250 toxic data points can sabotage a model's reasoning framework. To combat this, organizations must combine comprehensive data lineage tracking with blockchain-based immutable ledger technology to safeguard data integrity across the entire pipeline.
Once data preparation is complete, it's time to choose the right model. While many organizations gravitate toward the latest deep learning architectures, selecting a model that fits the data's actual characteristics is far more important. Overly complex models risk overfitting, which can paradoxically degrade real-world performance.
For datasets with fewer than 100 data points, traditional statistical models tend to outperform their more advanced counterparts. For longer sequences with thousands of observations, deep learning or foundation models become the better choice. In 2026, the industry standard is to optimize models using Weighted Absolute Percentage Error (WAPE) measured over 12-week inventory replenishment cycles.
ARIMA and Prophet remain highly effective for capturing clear seasonality and holiday effects, and they're ideal for rapid prototyping. XGBoost and LightGBM are preferred when interpretability matters, as they can quantify the influence of external variables through SHAP values.
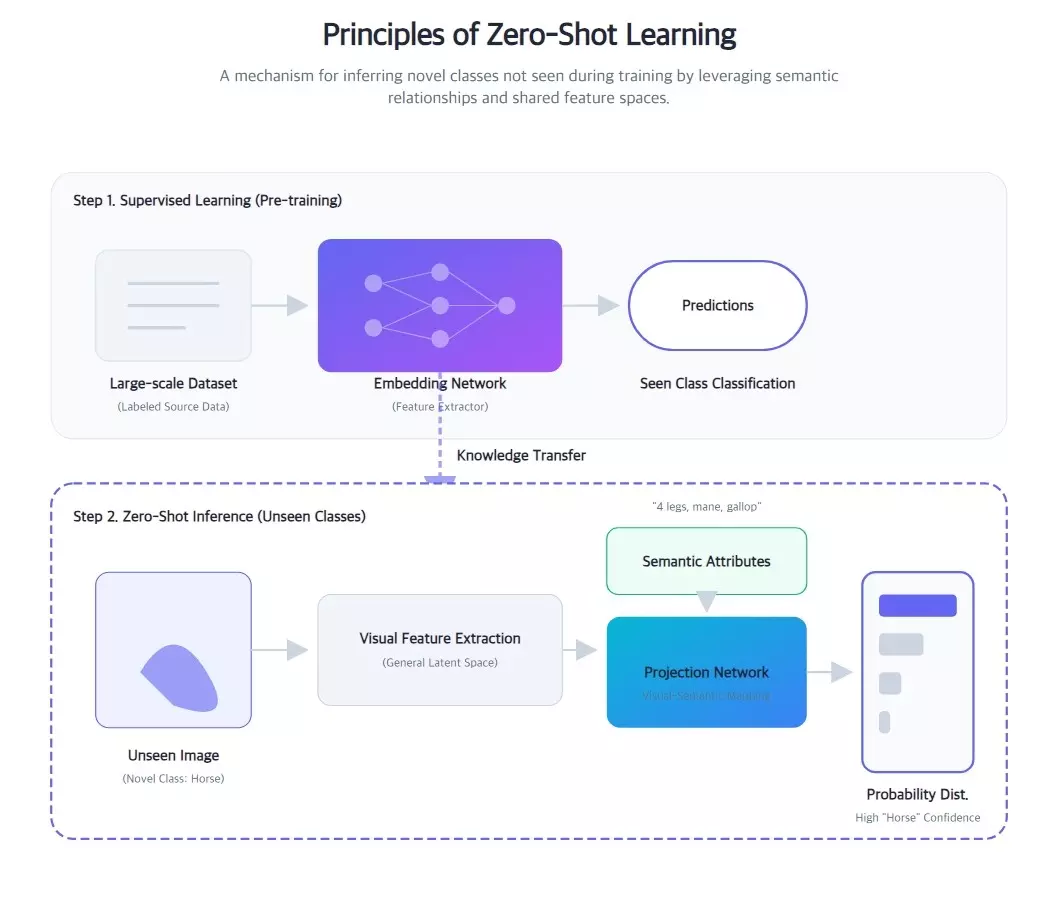
Conventional time-series forecasting models have always required extensive historical data to produce accurate predictions. But in scenarios involving new product launches, new market entries, or sudden environmental shifts—where historical data is scarce or nonexistent—these traditional approaches hit a wall.
Recent breakthroughs have made zero-shot forecasting a reality, powered by advances in large-scale models. These models are pre-trained on vast and diverse time-series datasets, enabling them to deliver generalized forecasting capabilities without explicit training on any specific domain. The leading zero-shot forecasting models gaining traction in demand forecasting include Amazon's Chronos-2, Salesforce's MOIRAI-2, and Time-MoE.
Amazon Chronos-2 learns time-series data as if it were language, delivering exceptional zero-shot forecasting performance. Salesforce MOIRAI-2 features a universal architecture that adapts flexibly regardless of the number of variables or periodicity. Time-MoE manages billions of parameters while maximizing computational efficiency, achieving over 45% error reduction in specific crop price forecasting benchmarks compared to previous baselines.
These advances in large-model-based zero-shot forecasting are dramatically lowering the barrier to entry for demand forecasting adoption. Companies that previously struggled to accumulate sufficient historical data can now leverage pre-trained models to build sophisticated forecasting systems from the outset—a pivotal enabler for faster decision-making and improved market responsiveness.
In real-world industrial applications, however, no single foundation model solves every problem. TSFMs excel at learning generalized patterns that perform well on average, but they have limitations when it comes to capturing structural characteristics unique to specific products—such as lumpy demand, strong seasonality, promotion-driven spikes and dips, or short product lifecycles.
Foundation models also fall short in explainability and decision-making connectivity. They produce forecast values, but they struggle to answer the kinds of questions business stakeholders need: "Why is demand for this item forecasted this way?" or "How would the forecast change if a specific variable shifted?"
For these reasons, there's a strong argument that the future lies not in "one big model" but in a model selection architecture. Practical demand forecasting systems from 2026 onward will increasingly maintain a portfolio of forecasting models, automatically selecting and combining the best-fit model for each product based on its data characteristics and demand patterns.
For example, TSFM-based zero-shot models can handle new products with minimal data. Domain-specific deep learning or statistical models serve well for core products with accumulated history. Dedicated lumpy-demand models address intermittent-demand products, while event-responsive models handle promotion-sensitive items.
In practice, hybrid approaches often deliver the strongest results—for instance, using SARIMA to capture linear trends and LSTM to learn the residuals. One major company achieved significant gains using exactly this methodology. Modern models are also increasingly integrated with LLMs, enabling automatic generation of natural-language explanations such as: "Demand is forecasted 20% higher this week due to rising temperatures and increased social media mentions." This kind of transparency builds critical trust with business teams.
The success of demand forecasting in 2026 is defined not merely by technology adoption, but by the emergence of a new role: the Intent Architect. This role translates business priorities into AI-readable instructions and orchestrates multiple AI agents as a central command function. Moreover, measuring ROAI (Return on AI Investment)—encompassing not just forecast accuracy but also inventory turnover improvements and overall business productivity gains—has become a critical success metric.
For AI-powered demand forecasting to deliver real results, two things matter most: how systematically you prepare your data, and how well you match models to that data.
The importance of data preparation cannot be overstated—it accounts for roughly 80% of a project's success. It's not just about collecting data; multiple elements must come together seamlessly for AI models to perform at their full potential.
When selecting models, chasing the latest technology is less important than aligning with the data's inherent characteristics. There is no single "best" model. The winning approach involves thorough data analysis, hands-on experimentation with multiple models, and selecting the one that delivers the best performance in real-world validation. In some cases, a straightforward Prophet model can outperform a complex Transformer. The wisest decisions factor in not only forecast accuracy but also business requirements, interpretability, and ease of maintenance.
ImpactiveAI's Deepflow is a solution that puts the data preparation and modeling strategies discussed above into real-world practice. It includes a library of over 224 AI models and autonomously analyzes data characteristics to select the optimal model for each use case.
With AutoML-driven selection from its 224+ model library, Deepflow automatically identifies the best-fit model—from SARIMA to TSFM—based on each organization's unique data profile. It integrates over 5,000 external variables, including economic indicators, weather data, and social signals, collecting them in real time to power advanced feature engineering. Its LLM-powered intelligent reporting replaces complex Excel-based workflows, dramatically accelerating decision-making speed.
The key to AI demand forecasting in 2026 isn't the complexity of the technology—it's execution. When data readiness, model selection, and agentic security work in harmony, organizations can enter the era of intelligent autonomous management.
.svg)


.svg)














