.svg)

.svg)
%202.svg)
What is the hyperparameter tuning technique for model optimization?

What is hyperparameter tuning?
Definition
In the modern manufacturing industry, artificial intelligence has become a key tool for improving productivity and quality control. Hyperparameter tuning is an essential process for tuning these artificial intelligence models to achieve the best performance.
Hyperparameter tuning is similar to the process of optimizing a factory's production facilities. Just as a production line adjusts temperature, pressure, and speed to produce the best product, AI models also require such detailed adjustments. This adjustment process is called hyperparameter tuning.
Features
Hyperparameters are the “external settings” of an AI model. Like the operating manual of a production facility, these are the values that must be set in advance by an expert before the system can operate.
For example, when operating an AI model for new drug development in the pharmaceutical industry, it is necessary to determine in advance how detailed the model should learn and how fast it should process information.
The experience and insights of domain experts are important for hyperparameter tuning. They must understand the characteristics of each industry and process and reflect them in the settings of the AI model.
Purpose and Importance
The ultimate goal of hyperparameter tuning is to maximize the performance of an AI model. For example, in the manufacturing field, hyperparameter tuning can improve the accuracy of defect detection and reduce the false positive rate in a defect detection system.
At the same time, it prevents the problem of overfitting, in which the model is overly tailored to the training data, or underfitting, in which the model fails to respond properly to new situations.
Proper hyperparameter tuning leads to direct business value.
For example, in chemical processes, AI models that predict reaction conditions can optimize raw material usage and increase energy efficiency through accurate hyperparameter tuning. This leads to lower production costs and improved quality.
Key hyperparameters of machine learning models
Each hyperparameter is not acting independently, but is closely related to each other.
For example, when using a large batch size, a larger learning rate is generally required, and when using a deep neural network, stronger regularization or dropout may be required. Therefore, when tuning hyperparameters, an integrated approach that takes these interactions into account is required.
Learning rate
The learning rate is a key hyperparameter that determines the speed at which the model finds the minimum value of the loss function during the learning process. It determines how much progress the model makes at each learning step.
If the learning rate is set too high, the model will try to find the optimal point quickly, but in the process, overshooting may occur, which is going beyond the optimal point.
On the other hand, if the learning rate is too low, the model will learn stably, but it may take a very long time to reach the optimal point or get stuck in a local minimum.
Generally, the learning rate is used between 0.0001 and 0.1. In many cases, it starts at 0.01 and is adjusted according to the performance of the model.
Recently, learning rate scheduling techniques that gradually reduce the learning rate during the learning process are also widely used.
Batch size
Batch size refers to the number of data samples processed in a single learning step. This directly affects the stability and speed of the model's learning.
Using a small batch size (32, 64) generates a lot of noise during the learning process, but this can help avoid local minima. It also has the advantage of low memory usage in resource-constrained environments.
Large batch sizes (128, 256) enable more stable learning and can improve learning speed through parallel processing. However, they require a lot of memory and can sometimes reduce the model's generalization performance.
Number of hidden layers and number of nodes in each layer
The number of hidden layers that determine the structure of the neural network and the number of nodes in each layer are important hyperparameters that determine the complexity and learning ability of the model.
As the number of hidden layers increases, the model can learn more complex patterns. However, too many layers can make learning difficult and increase the risk of overfitting. Generally, we start with 2 to 5 hidden layers and make adjustments gradually depending on the complexity of the problem.
The number of nodes on each layer determines the learning capacity of that layer. A large number of nodes can capture more complex characteristics, but increases the risk of overfitting and the computational cost. A structure that gradually reduces the number of nodes from the input layer to the output layer is usually used.
Dropout ratio
Dropout is a regularization technique to prevent overfitting, and it refers to the proportion of neurons that are randomly deactivated during the learning process.
Dropout prevents the model from over-reliance on certain neurons by temporarily removing neurons that are randomly selected during the learning process. It is similar to the effect of an ensemble of different models.
Generally, a value between 0.2 and 0.5 is used. A value of 0.5 produces the strongest regularization effect, but it also limits the model's learning ability. It is common to use a lower dropout rate for layers closer to the input layer and a higher rate for layers closer to the output layer.
Regulatory parameters
The regularization parameter limits the magnitude of the weights to prevent overfitting of the model and improve generalization performance.
L1 regularization penalizes the sum of the absolute values of the weights. This has the effect of making the model sparse by making some weights exactly zero. This is useful when feature selection is required.
On the other hand, L2 regularization penalizes the sum of the squares of the weights. This increases the stability of the model by keeping all weights small. This is the most commonly used regularization method.
The value of the regularization parameter is usually set between 0.001 and 0.1. The larger the value, the stronger the regularization effect, and the appropriate value should be selected according to the complexity of the model and the size of the dataset.
Importance of hyperparameter tuning
Hyperparameter tuning is a critical component for the successful development and operation of AI models. It has a wide-ranging impact, from optimizing model performance, balancing bias and variance, managing complexity, and ensuring practical applicability.
With a systematic and scientific tuning approach, companies can maximize the performance of their AI systems and ensure stable operation. This is a core competency that all organizations seeking AI-powered business innovation must pay attention to.
Model Performance Optimization
Hyperparameter tuning is a key process for maximizing the performance of AI models. By setting appropriate hyperparameters, predictive accuracy can be significantly improved and the generalization ability of the model can be enhanced.
It also allows you to efficiently utilize computing resources to shorten learning time and reduce costs. A systematic tuning process is essential because improper hyperparameter settings can lead even high-performance AI systems to fail.
Optimization of the bias-variance trade-off
One of the key goals of hyperparameter tuning is to find the optimal balance between the bias and variance of the model. Bias refers to the error between the model's prediction and the actual value, while variance refers to the variability of the model's prediction.
High bias causes the model to underfit, failing to capture important patterns in the data, while high variance causes the model to overfit, learning even the noise. Hyperparameter tuning can help you find the optimal balance between these two factors.
Systematic management of model complexity
Hyperparameter tuning effectively controls overfitting and underfitting of the model. By appropriately setting the regulatory parameters and dropout ratio, the model can be prevented from being overly fit to the training data.
At the same time, sufficient model complexity can be secured to prevent underfitting, which fails to capture important patterns in the data.
Hyperparameters directly control the complexity of the model. The learning rate determines the speed at which the model finds the optimal point, and the number of hidden layers and nodes determine the expressiveness of the model.
Regulatory parameters limit the complexity of the model to enable stable learning. By properly adjusting these factors, you can design the optimal model structure for the complexity of the problem.
Practical importance in the industrial field
The importance of hyperparameter tuning is proven in various industries. In the medical field, it plays a key role in improving the accuracy of diagnostic models, and in the financial sector, it is essential for ensuring the reliability of risk assessment models.
In e-commerce, it contributes to improving customer satisfaction by improving the performance of recommendation systems.
Hyperparameter tuning also plays an important role in academic research. Proper hyperparameter settings ensure reproducibility of research results and increase the reliability of scientific conclusions.
It has become standard practice in the research community to clearly report hyperparameter settings and systematically document the tuning process.
Hyperparameter tuning methodology
Manual Tuning
Manual tuning is the most basic method in which data scientists directly set and adjust hyperparameter values. This method involves selecting hyperparameter values based on domain knowledge and experience, and finding the optimal value through repeated experiments.
This method is effective when dealing with small models or a small number of hyperparameters. It also has the advantage of allowing you to gain a deeper understanding of the characteristics of the model and the impact of hyperparameters through a trial-and-error process. However, it is time-consuming and has the limitation of being difficult to find the optimal value in complex models.
Grid Search
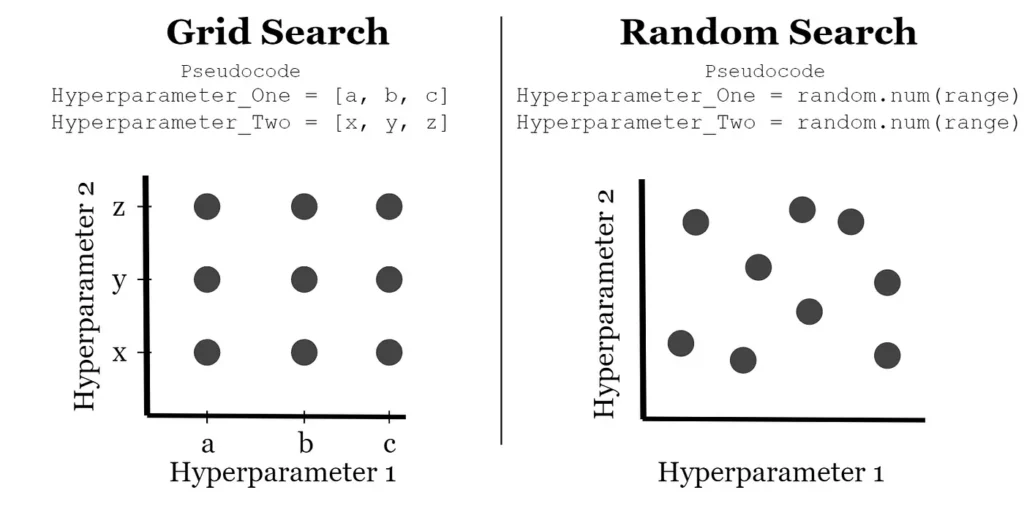
Grid search is a method of systematically exploring all possible combinations of hyperparameters. For each hyperparameter, the values to be explored are predefined, and the model is trained and evaluated for all possible combinations of these.
This methodology has the advantage of allowing for systematic and comprehensive exploration and is simple to implement. However, as the number of hyperparameters increases, the number of combinations to be explored increases exponentially, making the computational cost very high.
This can be particularly inefficient in large hyperparameter spaces.
Random Search
Random search is a method of searching by randomly selecting combinations in the hyperparameter space. After defining the range of each hyperparameter, the experiment is conducted by randomly sampling values within that range.
Random search is more computationally efficient than grid search, and is especially effective when some hyperparameters have a more significant impact than others. It also works relatively efficiently in a large search space, and can more effectively explore the region of important hyperparameters.
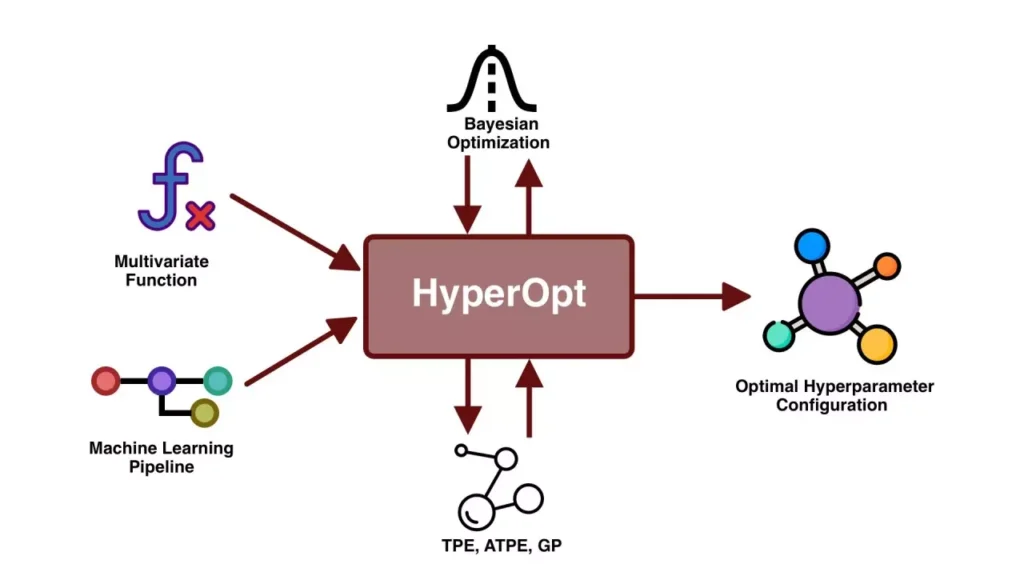
Bayesian Optimization
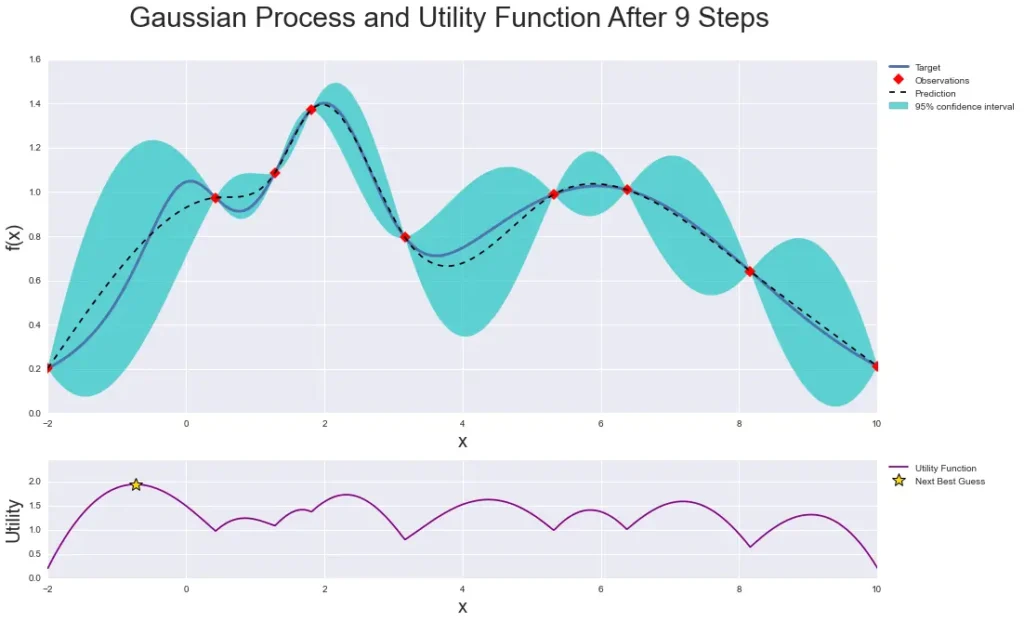
Bayesian optimization is an intelligent way to select the hyperparameter combinations to explore in the next experiment using the results of the previous experiment. It uses a probabilistic model to learn the relationship between hyperparameters and model performance, and then predicts the most promising hyperparameter combinations based on this.
This method can efficiently utilize computational resources and has the advantage of converging to the optimal point faster by considering previous evaluation results. It is especially useful when the cost of the experiment is high.
Hyperband
Hyperband is an improved method of random search, an algorithm that efficiently utilizes limited resources to find the optimal hyperparameters. It explores various combinations of hyperparameters in parallel and eliminates combinations that are not promising early on through initial performance evaluation.
It works by gradually shrinking the search space while allocating more resources to promising combinations. It is especially effective in situations where computing resources are limited, and it can optimize the balance between search and utilization.
Considerations when selecting a methodology
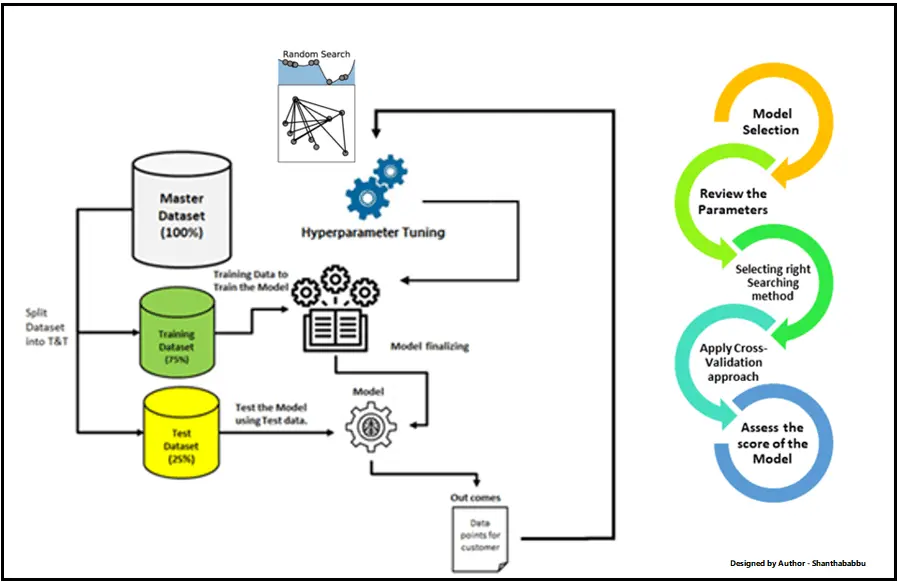
When choosing the optimal tuning method, the following factors should be considered.
- Number of hyperparameters and size of the search space
- Amount of available computing resources
- Time required to train the model
- Required level of model performance
- Time constraints of the project
Each methodology works better in certain situations, so you need to choose the right method by considering the characteristics and constraints of the project. Sometimes it can be effective to use a combination of multiple methods.
For example, at the beginning, you can perform a rough search with a random search, and then apply Bayesian optimization to promising areas.
The choice of hyperparameter tuning methodology has a significant impact on the success of a project. It is important to understand the characteristics, advantages, and disadvantages of each method and choose the most suitable method for the given situation.
In particular, the optimal tuning strategy should be established by comprehensively considering the size of the project, resource constraints, and time constraints.
Limitations of Hyperparameter Tuning and How to Overcome Them
Limitations
The most fundamental problem with hyperparameter tuning is that it is impossible to fully understand the optimization space. The impact of each hyperparameter on model performance is nonlinear and interacts with other hyperparameters in complex ways.
What is even more serious is that this relationship changes dynamically depending on the dataset and problem domain. Therefore, the optimal settings found in one problem may produce completely different results in another.
As the number of hyperparameters increases, the search space expands exponentially. This goes beyond the issue of simple computational cost and leads to fundamental difficulties in finding the optimal point. In high-dimensional spaces, meaningful sampling becomes extremely difficult, making effective exploration almost impossible.
This problem is particularly acute for the latest deep learning models, which have to deal with dozens or even hundreds of hyperparameters.

Most current hyperparameter tuning is based on a single or a small number of performance metrics. However, the quality of a model in real-world applications includes various aspects such as accuracy, processing speed, resource efficiency, and interpretability.
It is essentially impossible to reduce such a multi-objective optimization problem to a simple scalar metric. Moreover, over-optimization for a specific metric can sacrifice other important properties.
Most hyperparameter tuning methods assume a static environment. However, in a real operating environment, the data distribution changes over time, and system requirements also change dynamically. Current tuning methodologies do not effectively respond to these dynamic changes and require continuous readjustment.
How to overcome
In order to overcome the fundamental limitations of hyperparameter tuning, innovative approaches have recently emerged in the field of AI. In particular, the development of meta-learning, AutoML, and neural architecture search technologies is opening up new horizons for hyperparameter optimization.
The meta-learning approach learns tuning experience from various problems and datasets, enabling it to quickly infer effective hyperparameter settings even in new situations. This is similar to how an experienced data scientist makes intuitive decisions based on past experience.
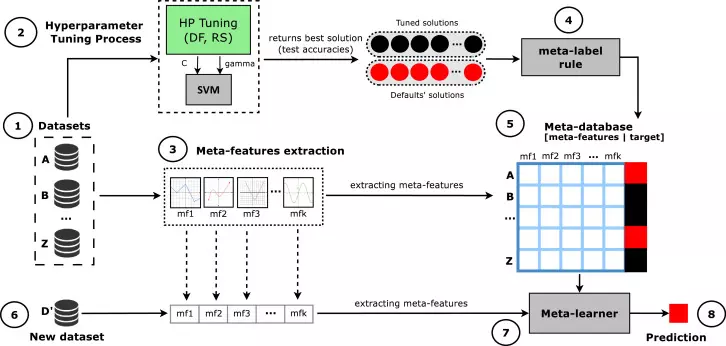
Recently, these meta-learning techniques have been combined with AutoML systems to provide even more powerful automated solutions.
The advancement of AutoML technology is completely redefining the process of hyperparameter tuning. Beyond the traditional manual tuning or simple automation tools, AutoML can optimize the entire model development pipeline.
Google's Cloud AutoML, H2O.ai's Driverless AI, and platforms like DataRobot automate the entire process from feature selection to model structure design to hyperparameter tuning. These tools can find the optimal model configuration without human intervention by using reinforcement learning and evolutionary algorithms.
Furthermore, the development of adaptive and dynamic tuning systems is also noteworthy. These systems detect changes in the operating environment in real time and automatically readjust the hyperparameters.
Recently, there has been a trend towards the integration of neural architecture search and hyperparameter tuning.
This allows for the simultaneous optimization of the model's architecture and hyperparameters, resulting in more efficient and powerful AI systems. For example, projects such as Google's AutoML-Zero and Microsoft's FLAML are demonstrating the potential of this integrated approach.
In recent years, there has also been a trend towards the integration of neural architecture search and hyperparameter tuning. This allows for the simultaneous optimization of the model's architecture and hyperparameters, resulting in more efficient and powerful AI systems. For example, projects such as Google's AutoML-Zero and Microsoft's FLAML are demonstrating the potential of this integrated approach.
These new approaches offer the possibility of overcoming the traditional limitations of hyperparameter tuning. In particular, it has become possible to develop high-performance AI models even in small and medium-sized enterprises or organizations that lack AI experts.
However, these automation tools do not solve all problems. Domain expertise and a basic understanding of AI are still essential, and a new type of expertise is required to effectively utilize automation tools.
In the future, this field is expected to develop further, accelerating the automation and intelligence of hyperparameter tuning. In particular, through the combination with explainable AI, it is expected to develop in a direction that allows the rationale for automated tuning decisions to be understood and verified.
IMPACTIVE AI will also continue its research to contribute to increasing the reliability and transparency of AI systems.
.svg)


.svg)














