.svg)

.svg)
Download Brouchure
%202.svg)
Oops! Something went wrong while submitting the form.

We frequently hear from organizations that their demand forecasting systems aren't delivering the accuracy they expected. Most immediately point fingers at data quality—suspecting insufficient data volume, missing information, or hidden outliers. Data quality certainly matters. Yet when meticulous data cleaning and enrichment still fail to improve forecast accuracy meaningfully, the real culprit often lies elsewhere: with the forecasting model itself.
Recent research reveals a striking insight. The accuracy of demand forecasts hinges not on the quality of raw data, but on how well your chosen model aligns with your data's inherent characteristics. While advanced machine learning and deep learning models have lifted average accuracy, they consistently struggle with sparse data, intermittent demand patterns, and extreme values. A 2024 University of Melbourne study on water demand forecasting illustrates this perfectly. Multiple state-of-the-art machine learning models performed well overall yet failed systematically when predicting unusually high or low demand. The data wasn't flawed—the models simply didn't match the data's patterns.
Many organizations rely on traditional statistical methods or relatively simple machine learning approaches. These work reasonably well for regular, repeating patterns but rarely capture the full complexity of real business environments. Published research consistently identifies model-data misalignment, overfitting and underfitting, inability to handle extreme scenarios, underutilized external variables, and poor model interpretability as key culprits behind forecast inaccuracy. The message is clear: no matter how good your data, choosing a model poorly aligned with your data's characteristics makes accurate forecasting difficult.
Quality data undeniably forms the foundation for accurate predictions. Historical sales records, inventory levels, and market trends certainly help. But here's the critical truth: however rich your dataset, the model must do the real work of extracting meaningful patterns about the future.
Consider a fashion retailer with three years of sales data, complete with seasonal patterns, promotion records, and weather information. A simple regression model can capture average sales trends. But what happens when fashion shifts, competitors launch new products, or a social media trend emerges around specific items? The data exists, yet without a model capable of grasping these complex dynamics, accurate forecasting becomes impossible. Data provides raw material; the model determines what insights you extract from it.

Recent research points to a fundamental problem: models often fail to match data patterns appropriately. Deep learning models like LSTM excel at learning typical patterns but struggle with out-of-sample extremes and abrupt structural shifts. This happens because these models excessively learn the noise inherent in "normal" conditions—a classic overfitting problem.
Conversely, simple statistical or shallow machine learning models miss the complex hidden structures in data. When dealing with multivariate time series involving nonlinear interactions between seasonality, promotions, and external factors, these models suffer from underfitting, overlooking critical patterns entirely. Research on intermittent demand forecasting confirms that machine learning models struggle when data is sparse and entropy is high, making reliable parameter estimation difficult and predictions unstable.
This stems from a fundamental mismatch between model complexity and data characteristics. Overly complex models absorb unnecessary noise; oversimplified ones miss essential patterns. The solution isn't collecting more data—it's selecting the model that best matches your data's true complexity and patterns.
Business reality often hinges on the exceptional, not the typical. The moments that matter most—sudden demand spikes or drops—significantly impact inventory management and production planning. The 2024 Melbourne water demand study demonstrates this precisely. Advanced machine learning models delivered solid overall performance but consistently misfired when demand became abnormally high or low.
Standard machine learning architectures weren't designed to handle irregular patterns where demand vanishes entirely then suddenly surges. Consequently, accuracy deteriorates precisely when operational stakes are highest.
Structural breaks and regime shifts present another critical risk, repeatedly highlighted in deep learning demand forecasting literature. Models trained on historical data lose reliability when consumer behavior shifts, policies change, or external shocks occur. Most standard architectures lack built-in mechanisms to detect or respond to such transitions.
Demand doesn't depend solely on historical sales patterns. Economic growth rates, exchange fluctuations, energy prices, and policy changes all influence demand. Yet many experts note that existing models often rely primarily on historical extrapolation while inadequately reflecting causal relationships.
Decision Tree-based models, common in demand forecasting, exemplify this gap. While machine learning theoretically handles weather, macroeconomic indicators, and social data, practice shows these models overwhelmingly depend on past demand. This limitation reduces the models' potential value. Additionally, interventions like promotions, price changes, and campaigns are often coded too simplistically. A promotion represented as a single flag value means models cannot properly learn demand surge patterns during promotions or post-promotion dips. This necessitates additional data correction work.
A 2025 Nature paper on hybrid weighted ensemble frameworks offered important insights. Combining models that each effectively capture temporal dynamics and multiple input variable impacts genuinely improves forecast accuracy. This means integrating external variables effectively through appropriate model architecture matters as much as including the variables themselves. The choice of external variables and how your model learns them both drive performance.

Low accuracy pairs with another serious issue: inability to understand why models generate specific outputs. Research from 2024-2025 on demand forecasting reveals that deep learning models function as black boxes, making prediction processes opaque and preventing teams from identifying and correcting errors effectively.
When a model cannot explain its predictions, rectifying failures becomes guesswork. A 2025 supply chain forecasting framework study demonstrates that applying explainable AI techniques like SHAP reveals which factors influenced predictions and their contribution magnitudes, enabling evidence-based decision-making.
Interest in interpretable models has surged recently, with explainability now matching accuracy in importance for demand forecasting. Model selection must therefore consider not just predictive power but also result transparency. Choosing models aligned with data characteristics while remaining interpretable enables organizations to continuously learn and improve. Without this transparency, forecasting becomes a black box that teams cannot improve.
Overcoming the limitations research has revealed requires a different perspective. The demand forecasting field increasingly prioritizes advanced AI models with data-specific architectures rather than merely complex structures.
Transcending these limitations demands more than added model complexity. It requires deeper data understanding and novel learning approaches. Industry attention is shifting toward advanced models specifically designed for data characteristics—not for complexity's sake, but for data-informed architecture.
Many models still inadequately handle long-range temporal dependencies. Early RNN models processed sequential data yet failed to learn the medium-to-long-term patterns essential for demand forecasting.
This gap prompted GRU and LSTM architectures, designed to capture time-dependent pattern shifts more effectively. However, these still rely on recurrent structures, creating fundamental limitations in learning extended time series dependencies.
Recent breakthroughs like I-Transformer and TFT, based on transformer architectures, have overcome many constraints. Their attention mechanisms effectively identify long-range temporal patterns. They capture complex relationships—like promotion effects persisting months later or inventory impacts on sales—that traditional architectures miss.
Transformer-based models do carry trade-offs. Their complexity means larger model sizes, longer training times, and heavier computational demands. Therefore, selecting between models requires carefully considering your data's long-term pattern complexity and target accuracy levels. Simpler data warrants GRU or LSTM; complex long-range dependencies benefit from transformer approaches.
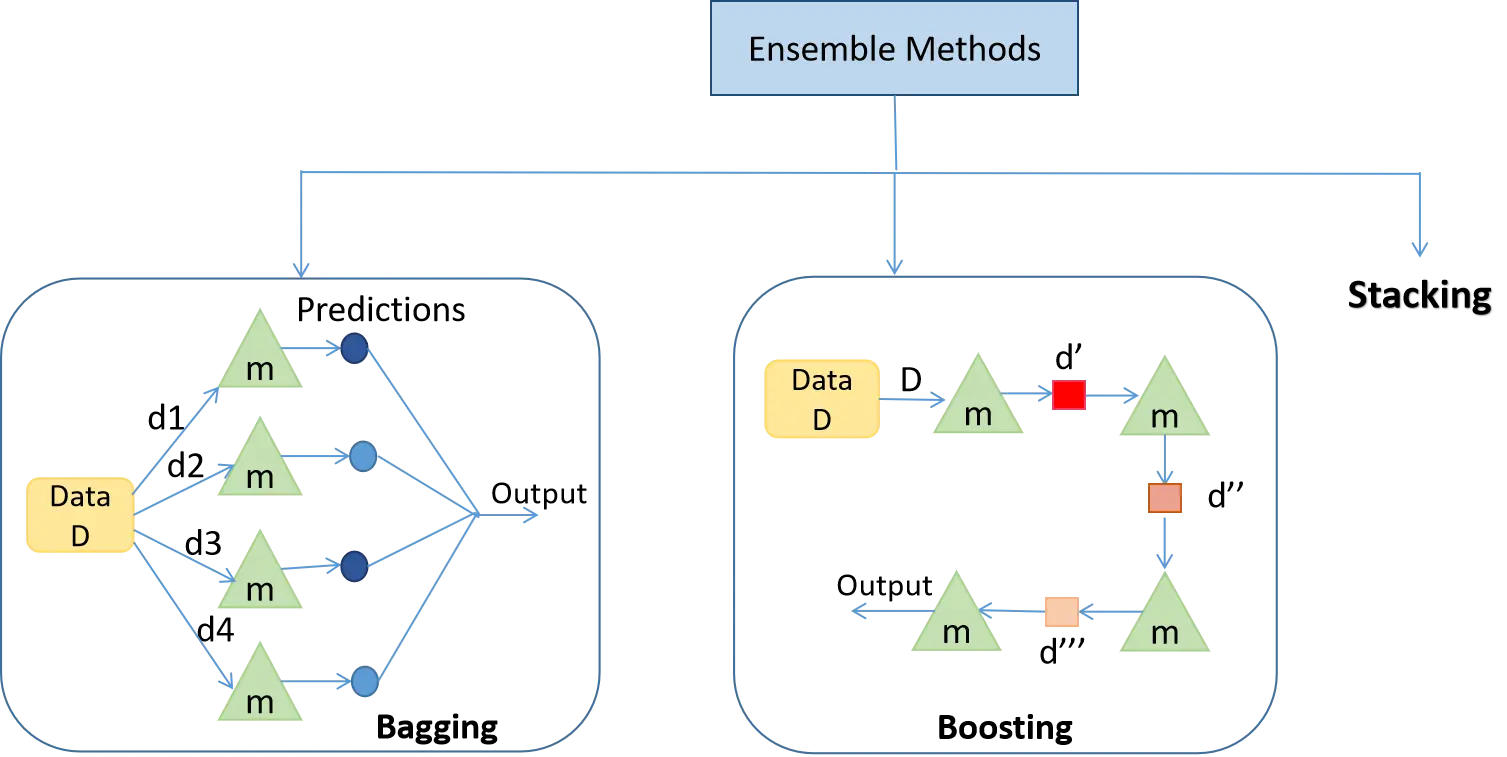
The evidence is conclusive: no single model architecture delivers optimal performance across all products, forecast horizons, and demand types. LSTM, MLP, SVR, or any individual model will fail on specific data segments. Applying one "global" model universally degrades performance where it's least appropriate.
Hybrid ensemble research demonstrates that blending statistical and machine learning models more effectively captures diverse demand patterns. This hybrid approach sidesteps the fundamental constraints of single-model thinking.
Since single models cannot overcome inherent limitations, automated pipelines train multiple models simultaneously and identify optimal combinations. Different products and SKUs truly require different best-fit models—manual selection across hundreds or thousands of products is practically impossible.
Automated pipelines handle data preprocessing, feature engineering, model training, and evaluation simultaneously. They rapidly evaluate millions of combinations, identifying each product's ideal forecasting model. As new data arrives, models automatically retrain, incorporating the latest information.
Recent evolution extends beyond simply trying varied models to strategically combining models with complementary strengths. One model excels at capturing seasonality; another reads trends exceptionally; a third effectively incorporates external variables. Combined intelligently, their diverse strengths compensate for individual weaknesses, yielding significantly more accurate results.
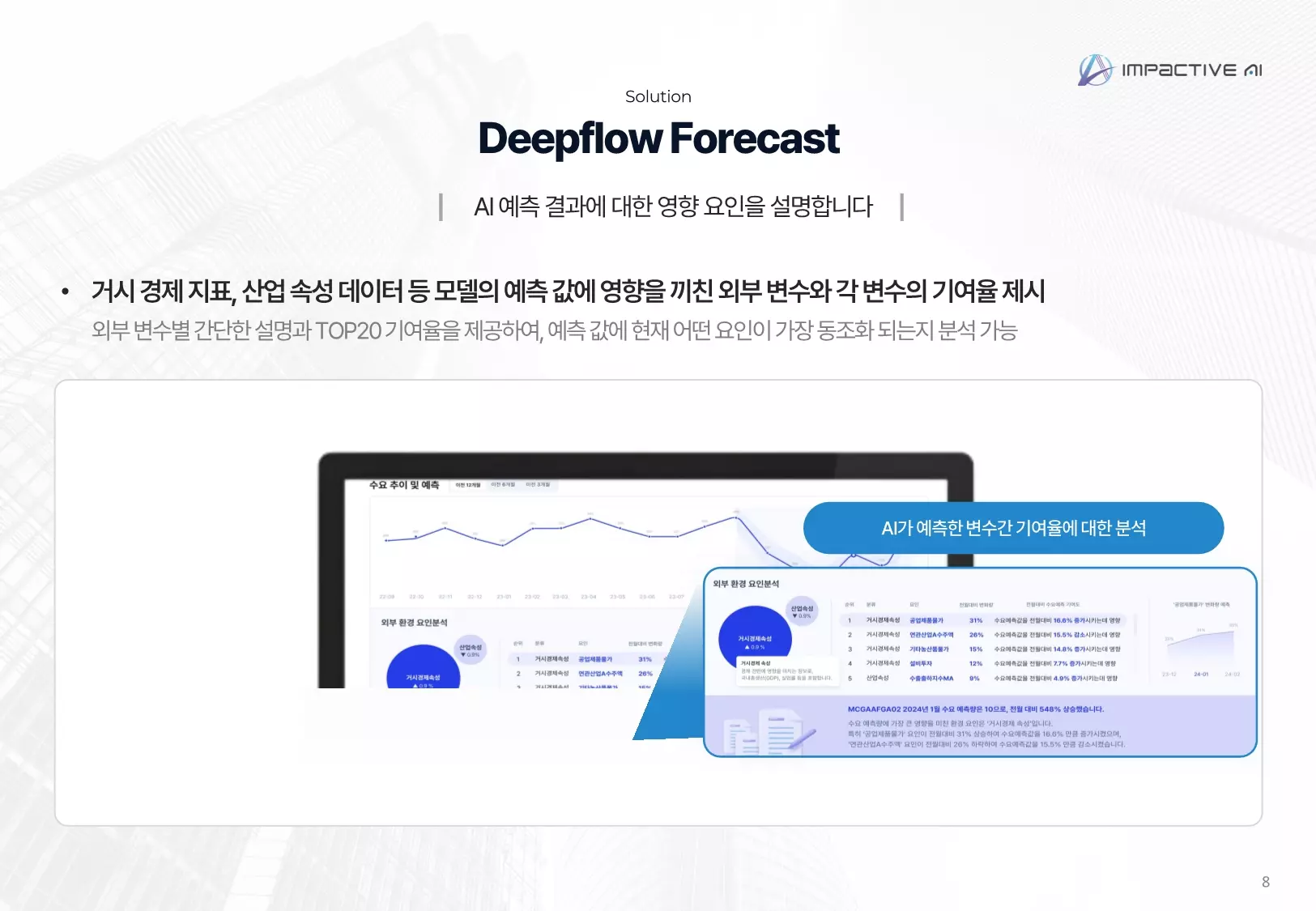
ImpactiveAI has spent five years developing specialized demand and price forecasting technology. Currently holding 67 patents and leveraging 224 advanced AI models, the Deepflow solution delivers recognized accuracy across manufacturing, retail, and supply chain management.
Deepflow Forecast employs hybrid ensemble architecture. It combines transformer-based time series models like I-Transformer and TFT with multiple deep learning architectures including GRU, DilatedRNN, TCN, and LSTM. Rather than depending on a single model, 224 models compete, with the system selecting the best match for each product and situation.
Deepflow directly addresses model interpretability limitations identified in academic research. External variables—macroeconomic indicators, weather, market trends—aren't simply added; the system quantifies each variable's contribution to predictions. This transparency makes forecast reasoning clear and greatly reduces interpretation difficulty.
Real implementations demonstrate impressive results. Raw material price forecasting achieved up to 98.6% accuracy while reducing inventory imbalances by an average of 33.4%. One client reduced monthly inventory costs by 24.8 billion won with dramatically improved operational efficiency.
Deepflow's defining advantage lies in forecast explainability. Like explainable AI—an industry trend—it reveals which variables grounded each prediction and their specific contribution levels. This transparency goes beyond numbers to demonstrate causation, enabling real-world trust and application. Organizations can consequently improve models continuously and deploy forecasts strategically.
Even the most advanced technology remains theoretical until applied to your actual company data. Therefore, ImpactiveAI offers a limited-time free PoC program enabling verification of AI demand forecasting through Deepflow's foundational models.
This program lets you directly experience AI demand forecasting using real company sales and demand data, typically completed within two weeks. More than 200 advanced AI models automatically train, with the system automatically selecting the optimal model. You'll witness inventory cost reductions exceeding 30% and operational time compression to roughly one-sixth of previous levels. A detailed report analyzing results and key influencing factors accompanies the PoC.
The process is straightforward. Request free consultation through the PoC application page. Our team contacts you with data requirements guidance. Provide data as directed, and AI conducts two weeks of demand forecasting. Upon completion, you receive PoC results via email, followed by a session explaining the forecast results and key findings.
Improving demand forecast accuracy demands focusing on data quality, but equally importantly, selecting models aligned with your data's characteristics.
Problems like overfitting, underfitting, extreme value blind spots, insufficient external variable utilization, unexplainable prediction mechanisms, and single-architecture limitations typically stem from data-model misalignment. Even excellent data yields disappointing accuracy when paired with poorly matched models.
Conversely, advanced AI models precisely aligned with data characteristics—particularly hybrid ensemble approaches intelligently combining multiple methodologies—enable far more accurate and trustworthy forecasts from identical data. Recent research emphasizes that transformer-based time series models, strategic architecture combinations, and explainable AI techniques grow increasingly critical.
If your current forecasting system disappoints, before collecting or refining additional data, first verify you're using the model best suited to your existing data. Through ImpactiveAI's two-week free PoC program, experience how advanced AI models reflecting cutting-edge research can transform your actual business outcomes.
.svg)


.svg)













