.svg)
Download Brouchure
%202.svg)
Oops! Something went wrong while submitting the form.

Demand forecasting is an essential scientific approach for companies to foresee the future and manage uncertainty. It provides the foundation for establishing rational plans for core business activities such as product demand, inventory planning, and workforce allocation by analyzing past data to identify market trends. In an environment of rapidly changing customer demand, accurate demand forecasting enables inventory management optimization and personalized product recommendations, creating business value. Improved forecasting accuracy contributes to minimizing inventory losses, maximizing production and supply chain planning efficiency, and enhancing customer satisfaction and corporate profitability. Therefore, improving demand forecasting accuracy is a core challenge for all companies and an essential element for securing competitive advantage.
The performance of demand forecasting models is critically dependent on the quality and utilization methods of input data. The completeness and degree of data usage have a profound impact on prediction accuracy. Recently, generative artificial intelligence (AI) technology has been continuously improving prediction accuracy by learning vast amounts of big data, but this is only possible when high-quality data is provided as a prerequisite.
In the data utilization era, AI performance is significantly affected not only by data quantity but also quality, and data reliability and utility determine the success of prediction models. This article presents core data principles for improving demand forecasting accuracy and specific measures for applying them to actual business, aiming to help companies strengthen their data-driven decision-making capabilities and respond agilely to market changes.
Accurate and reliable demand forecasting begins with high-quality data. Data quality is a multidimensional concept that goes beyond simply having data exist, indicating how reliable and useful it is for business decision-making. The following are essential core data quality principles for demand forecasting.
Accuracy is a metric that measures how closely data points reflect reality. This means there are no systematic errors in the data. If demand forecasting models learn data that is disconnected from reality, the prediction results themselves can diverge from reality and distort business decision-making.
For example, a model trained on data where past sales volumes are consistently overestimated or underestimated compared to actual figures can cause serious disruptions to inventory management and production planning.
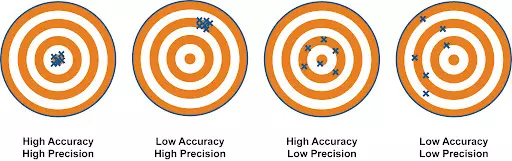
Accuracy measures how close data points are to actual values and aims for no systematic errors, while precision focuses on measurement consistency and means minimizing random errors. In demand forecasting, both accurate predictions that are close to actual values (accuracy) and consistent prediction results (precision) are important.
To increase prediction model reliability, it's necessary to check not only that predicted values are close to actual values but also whether prediction results show consistent deviations and patterns across various situations and time points. If predictions work well only in specific situations but have large prediction deviations in other situations making them unreliable, this indicates low precision. Therefore, both accuracy and precision indicators should be considered when evaluating and improving prediction model performance.
Completeness is a metric that evaluates the proportion of missing values within a dataset. Incomplete data can lead to biased analysis, causing distortions in model learning and seriously undermining prediction accuracy. For example, if sales data for specific periods is missing, demand patterns or seasonality for those periods cannot be properly learned, resulting in prediction errors.
Missing values can be replaced (imputed) with statistics such as mean, median, or mode, or filled using machine learning techniques through prediction models. However, simply filling missing values is not always the solution. Understanding the type of missing data is important. When data is missing completely at random (MCAR), removal is possible, but for missing at random (MAR) where correlation with other variables allows estimation, or missing not at random (MNAR) where missing is related to the value of the missing variable itself, more complex imputation strategies or causal analysis are needed.
Imputed data can introduce uncertainty, and replacement with representative values may lead to incorrect statistical conclusions. Therefore, careful choices are needed between data loss and bias risks, and the most appropriate processing strategy that fits the business context should be established considering the 'type', 'proportion', and 'cause' of missing data. If too many values are missing or unreliable, deletion of corresponding rows or columns should be considered, but it should be recognized that this can lead to reduced degrees of freedom and decreased statistical power.
If you're curious about effective methods to start demand forecasting even in situations with absolutely insufficient data, please check [Small Business Customized Demand Forecasting That Can Start Even with Insufficient Data].
Consistency means data should maintain uniformity without contradictions or inconsistencies across various sources, periods, and measurement criteria. Inconsistencies due to manual input errors or system failures can reduce data analysis reliability and cause models to learn incorrect patterns.
For example, if a customer's location is displayed as 'New York' in the Customer Relationship Management (CRM) system but the shipping address is displayed as 'NYC', this can confuse regional demand analysis and undermine prediction accuracy. Cross-validation with external sources or historical data is important to identify and correct such inconsistencies.

Timeliness is a metric indicating how up-to-date data is. Timeliness is particularly important in dynamic domains such as stock trading, social media analysis, and demand forecasting. Latency from data collection to availability can impair prediction models' ability to respond quickly to changing market conditions.
Prediction frequency varies according to data granularity (daily, weekly, monthly) and is closely connected to timeliness. High granularity and timeliness (daily predictions) are essential for short-term operational decisions such as inventory management or workforce scheduling.
Conversely, monthly or quarterly predictions may be sufficient for strategic decisions such as resource allocation or marketing campaign planning. If data is too granular, there's risk of overfitting due to noise, increased data collection and processing effort, and costs. Conversely, if too coarse, important fluctuations may be missed.
This trade-off between timeliness and granularity is not simply a technical issue but means finding optimal balance points according to prediction 'business purposes'. For example, initial demand forecasting for new products requires high timeliness and daily granularity to capture rapid changes, but predictions for essential goods with stable demand may be sufficient with less frequent updates. This emphasizes that data strategy should be closely linked with business strategy, and managing all data with the highest granularity and timeliness is not always the optimal solution.
If you want to learn more about techniques for improving prediction accuracy using time series data, please refer to [How to Improve AI Prediction Accuracy Through Time Series Data Augmentation].
Validity means data should comply with defined rules or constraints and be relevant and appropriate in business contexts. It's important to define business rules and apply them to data to verify data validity.
For example, rules such as age must be positive or email addresses must contain "@" symbols can prevent meaningless text or irrelevant content from entering prediction models.
Validity is not a fixed concept but can change dynamically. As markets change, data validity criteria should also be reevaluated. Proving data validity through generative AI appliances and continuously managing it according to market changes can be a good solution for maintaining demand forecasting accuracy.
AI can be utilized as a tool that automates and improves data quality management itself, beyond simply being used as input for prediction models. This emphasizes AI's active role in securing data quality and shows that continuously verifying and managing data validity is essential for maintaining prediction model reliability. If you're curious about actual application cases of AI-based data management, please refer to [Data Augmentation Cases You Must Know Before AI Implementation].
Uniqueness means there should be no duplicate records within a dataset. Duplicate data can distort analysis, inflate counts, and introduce bias, seriously undermining prediction model accuracy. For example, if the same customer information is entered twice in a customer database, it can lead to incorrect customer segmentation, reducing the accuracy of personalized demand forecasting.
To solve these problems, techniques such as fuzzy matching or hashing should be used to identify and remove duplicate items. AI algorithms are effective in improving data quality by finding and correcting duplicates in datasets.
Based on high-quality data principles, the process of comprehensively collecting and systematically preprocessing data suitable for prediction models is essential for maximizing demand forecasting accuracy.
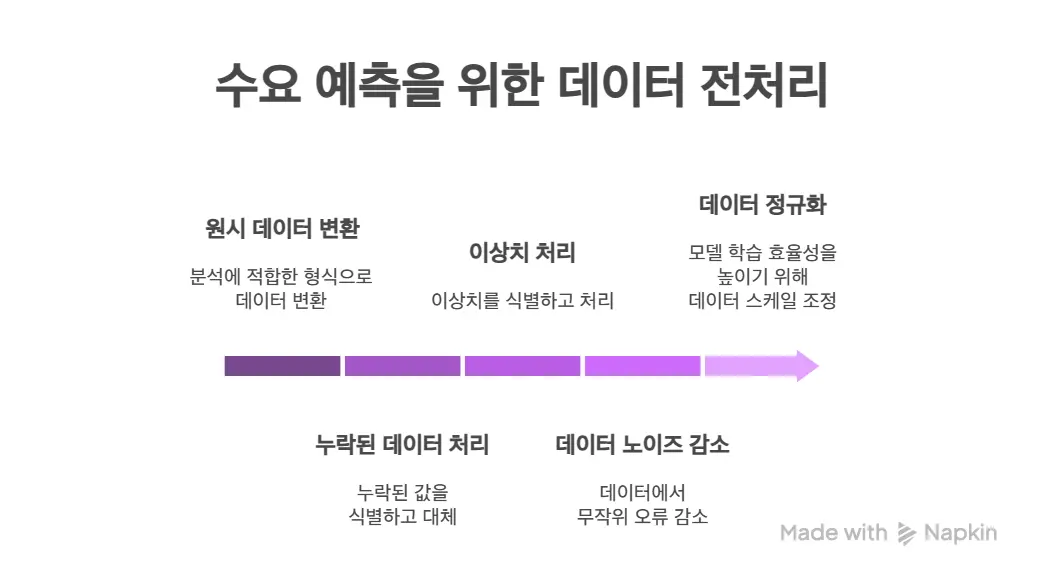
To improve demand forecasting accuracy, it's important to collect and integrate as much relevant internal and external data as possible. Internal data includes past sales volumes, product details, prices, promotions, inventory, and location information. External data can utilize economic indicators, weather, competitor activities, social media trends, search term data, and traffic conditions.
Collected raw data should be aggregated in appropriate ways such as sums and averages according to the frequency of prediction problems (e.g., daily, weekly), and AI can be utilized to automate heterogeneous data integration.
This is the process of transforming raw data into forms suitable for analysis to improve demand forecasting model performance.
Missing Data Processing: Identify missing values in datasets and replace (impute) them with mean, median, prediction models, etc., or consider deletion if too many or unreliable. Understanding types of missing data (MCAR, MAR, MNAR) and applying appropriate strategies is important.
Outlier Processing: Identify outliers that extremely deviate from data distribution using box plots, Z-scores, etc., and process them through methods such as removal, value capping, or transformation (log transformation, etc.). Since outliers may represent actual business events, consulting with domain experts is essential.
Data Noise Reduction and Normalization: Reduce random errors (noise) and adjust data scales through normalization processes to improve model learning efficiency. Clear processing policies for special events such as promotions and product discontinuation should also be established.
This is the process of improving machine learning algorithm performance by analyzing characteristics or relationships of original data or utilizing domain knowledge to create new variables.
- Feature Extraction: Analyze relationships between existing features to create new linear or nonlinear combination variables, reducing data dimensions (e.g., PCA, LDA).
- Feature Selection: Select features most relevant to prediction from all features to reduce feature count (e.g., Filter, Wrapper, Embedded Method).
- Lag Feature Generation: Add past time point data to current time point data to reflect the impact of past sales volumes, prices, etc., on current demand.
- Derived Feature Utilization: Generate new meaningful features by combining or transforming existing features (e.g., log transformation, one-hot encoding, day of week/holiday status, etc.). Deep understanding of business context is important in this process.
Improving demand forecasting accuracy is a core challenge that directly impacts corporate operational efficiency, financial performance, and customer satisfaction. As presented in this article, the fundamental foundation for achieving such accuracy is data.
Data quality principles (accuracy, completeness, consistency, timeliness, validity, uniqueness), systematic data collection and preparation strategies (related data collection and aggregation, sophisticated preprocessing, in-depth feature engineering), and strong data governance systems supporting all of these work complementarily to maximize prediction model performance.
Particularly, it's important to simultaneously pursue data accuracy and precision, minimize bias through strategic processing considering types of missing data, and optimize the trade-off between timeliness and granularity according to business purposes. Additionally, feature engineering utilizing domain knowledge plays a decisive role in helping models learn meaningful patterns in business contexts, beyond simply transforming data.
Having data governance means ensuring all these data management activities are performed consistently and responsibly. In the AI era, AI forms an interdependent relationship where it becomes both a beneficiary and powerful tool for data governance.
Companies can continuously improve demand forecasting accuracy through the following recommendations:
1. Continuous Investment in Data Quality: Data is not something that ends once built but an asset that must be continuously monitored and improved according to constantly changing business environments. Data quality metrics should be regularly measured and evaluated, and quality degradation factors should be proactively identified and resolved.
2. Strengthening Cross-Functional Collaboration: Close collaboration between data scientists, business analysts, and domain experts is essential at all stages from data collection to feature engineering and prediction result interpretation. Deep understanding of business context should particularly accompany outlier processing and new feature discovery.
3. Establishing Data Governance Systems and Cultural Settlement: Building clear data principles, organizations with defined roles and responsibilities, and standardized processes is important. Furthermore, data governance should be internalized as part of organizational culture, encouraging all members to recognize data importance and contribute to quality maintenance.
4. Strategic Utilization of AI Technology: AI can be a powerful tool not only for improving prediction model performance but also for automating and optimizing data collection, integration, preprocessing, and governance processes themselves. Methods to increase data management efficiency and accuracy through AI-based solution implementation should be explored.
If you want to learn more about advantages, disadvantages, and selection criteria of various demand forecasting methodologies, please check [Demand Forecasting Methodology Comparison: Quantitative vs Qualitative Demand Forecasting].
By systematically applying these data principles and best practices, companies will be able to dramatically improve demand forecasting accuracy and achieve continuous growth through agile and effective decision-making even in uncertain market environments.
.svg)


.svg)